

Enter Unstructured. Specializing in extracting and transforming complex enterprise data from various formats, including the tricky PDF, Unstructured streamlines the data preprocessing task. This is not just about making the data extraction process less tedious. It’s about unlocking the potential of vast amounts of information hidden in PDFs and other formats, transforming them into AI-friendly JSON files ready for vector databases and large language model (LLM) frameworks. By reducing the preprocessing workload, Unstructured enables data scientists to channel their focus where it matters most: modeling and analyzing the data to drive actionable insights.
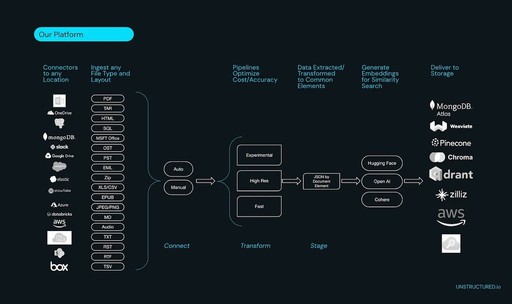
This guide aims to do just that. We’ll walk through the process of processing PDFs in Python, step by step, offering you the tools to wrestle that stubborn data into a structured, usable format. And while we delve into the ‘how’, we’ll also explore the ‘why’ — why opting for Unstructured is a prudent choice for data scientists striving for efficiency, accuracy, and ease in managing their data assets. So, if you’re tired of PDF-induced headaches and ready to take charge, read on. Let’s demystify the world of PDF data extraction together.
Before diving into the world of PDF data extraction, ensuring that your environment is primed is crucial. PDFs, being a complex format, often require specific libraries to handle their intricacies. Let’s set up our Python environment to ensure smooth sailing:
Python Version with pyenv: If you don’t have pyenv installed, it’s a great tool to manage multiple Python versions. Install it following the instructions here. Once done, install your desired Python version:
pyenv install 3.9.1